Redis Multi-node deployment: Replication vs. Cluster vs. Sentinels
There are two ways of using Redis:
- Using a single node deployment — where all the reads and writes happens from single machine
- Using a multi-node — where reads and writes can happen from multiple machine
It’s no brainer that single node deployment has three major problems:
- Scalability (Data size): When you have only one machine, it means your data should fit in that single machine
- Scalability (TPS): One machine has limited resource in terms of CPU, so it can support a limited number of “transaction per seconds” (TPS). If your reads/writes go beyond that limit, your machine/pipeline can fail
- Availability: When you are running everything on single machine, if that machine crashes, you will loose your Redis database
When you face any of the above 3 problems, you have only one option — use multi-node Redis deployment. The challenge is, there are 3 forms of Redis multi-node deployment and the choice depends on the problem that you are facing. The three multi-node deployment options are:
- Replication
- Cluster
- Sentinels
Replication

The diagram above shows a typical setup of master-replica multi-node deployment.
On the left we have master node — which handles all the writes and some reads.
On the right are 3 replica nodes — which handles reads and no writes.
Data that is written to the master node is sent to all the replicas in real-time so that all replicas have up-to-date copies of master data and can support read requests.
Few things to note about this setup are:
- All the writes are still handled by single server — so there is no improvement in writes/second
- Data is not divided among the nodes, instead all the data from master node is maintained as a copy in replica nodes — so there is no improvement in amount of data that can be stored
- If your master node goes down, all write requests will fail and replica node will continue to serve read requests (non-latest data, as new writes fail and will not go to replica nodes) — so your availability does not improve
- What improves is number of reads that your database can handle. So if your database was originally able to handle 1000 reads/second from single machine, since you have 4 machines (1 master + 3 replicas) — now you can handle 4000 reads/second (approximately)
So, if your problem is read scalability, you can go for Replication.
Cluster
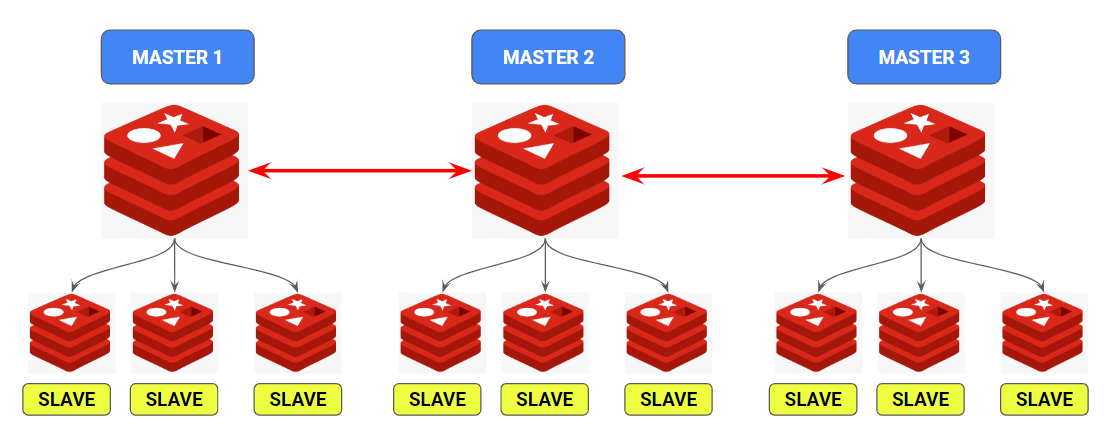
The diagram above shows a typical setup of Redis deployment in cluster mode.
There are multiple master nodes (3 in this case) and each master can have one or more multiple replicas (3 in this case).
Few things to note about this setup:
- Data is divided among the master nodes. So if you have 100GB of data; 30GB might be stored in Master1, 40GB in Master2 and 30GB in Master3 — so we have data storage scalability
- Since masters are solely responsible to process write requests and we have more than 1 master in the cluster — we have write/second scalability
- If a master node goes down, one of its replica node will be promoted as master — so there is increase in availability of your database even when there are node failures (these kind of systems are called highly-available systems)
In short, if your problem is data size not fitting on one machine or write scalability or high availability — go for cluster deployment
Sentinels
Redis sentinels are multi-node deployment where you can have high availability even with just one master node
We saw in the cluster mode, that high availability is achieved when during master node failures, one of the replica node is promoted as master. But this high-availability is achieved because we have multiple masters which are configured to talk among themselves (gossip protocol) and keep a watch on each other, do the failover (process of promoting replica as master) when a master has gone down.
But, maintaining multiple masters has its challenges too. Although going in details about them is out of scope for this discussion, but one challenge is — multi-key operation. Say, you perform a multi-key operation (like fetch two keys, update 2 keys, etc in single command), both keys should be in the same master; if not, the command will fail.
So, in cases where you don’t really need multiple masters (because your dataset is not large enough that it has to be distributed among multiple machines, or your write requests are small enough to be handled by one machine) but you do need a highly-available system — that is, when master fails, you still need you database to be up: that’s when you can use Redis Sentinels
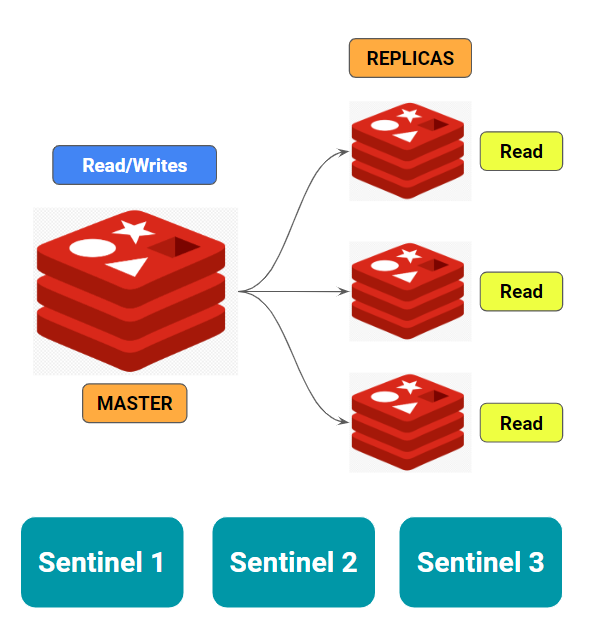
This is what a typical Sentinel deployment looks like. You have your regular redis deployment with one master and multiple replica, along with it you have Sentinel service running on different machines that is constantly monitoring the master node and talking among each other.
The moment one of the sentinel node is not able to reach master node, it will start the failover process by asking other sentinels to check if they also see the master as unreachable (generally a majority vote is required to proof that master is really not reachable).
Once the majority is reached, one of the sentinel will becomes a leader to do the failover process wherein it will appoint one replica as master and direct rest of the replicas to start using the new master.
So, in cases where high-availability is critical but write and storage limits have not reached — you can go for Sentinels.